Producto destacado
IntroducciónEl algoritmo de Viterbi permite encontrar las secuencia de estados más probable en un Modelo oculto de Markov (MOM), Consideremos la variable δt(i) que se define como:
δt(i) es la probabilidad del mejor camino hasta el estado i habiendo visto las t primeras observaciones. Esta función se calcula para todos los estados e instantes de tiempo.
Puesto que el objetivo es obtener las secuencia de estados más probable, será necesario almacenar el argumento que hace máxima la ecuación anterior en cada instante de tiempo t y para cada estado j y para ello utilizamos la variable A continuación se detalla el proceso completo utilizando las funciones δ y AlgoritmoInicializaciónδ1i = πibi(o1) donde Recursión
donde:
donde:
Terminación
Reconstrucción de la secuencia de estados más probable
donde:
Algunos de los cálculos del algoritmo de Viterbi recuerdan a los del algoritmo forward necesario para calcular eficientemente la probabilidad de una secuencia de observables. Una de las diferencias es la incorporación de la función Ejemplo de secuencia de estados más probable La figura muestra un ejemplo de secuencia de estados más probable en un Modelo Oculto de Markov de 5 estados dada un secuencia de observaciones de longitud 5.
Aplicación del algoritmo de ViterbiDesambiguación léxica categorialUna de las aplicaciones del algoritmo de Viterbi es en el área de procesamiento del lenguaje natural, más concretamente en el proceso de desambiguación léxica categorial. En este caso particular, los elementos de un Modelo Oculto de Markov serían los siguientes:
La figura siguiente muestra un ejemplo de etiquetado gramatical para la oración "Coto privado de caza"
En él, los observables son la secuencia de palabras de la oración. Se puede observar como para cada palabra se contempla sólo un conjunto limitado de posibles categorías gramaticales (caza puede ser o nombre o verbo). Este es debido a que la probabilidad de pertenencia de determinadas palabras a una categoría gramatical es nula (como la probabilidad de que la palabra caza sea adverbio). Esto simplifica enormemente los cálculos en el modelo. Otras preguntas fundamentalesOtros dos problemas que es importante saber resolver para utilizar los MOO son:
Véase tambiénEnlaces externos
Categoría: Bioinformática |
|
| Este articulo se basa en el articulo Algoritmo_de_Viterbi publicado en la enciclopedia libre de Wikipedia. El contenido está disponible bajo los términos de la Licencia de GNU Free Documentation License. Véase también en Wikipedia para obtener una lista de autores. |



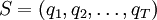 , a partir de una observación
, a partir de una observación 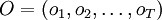 , es decir, obtiene la secuencia óptima que mejor explica la secuencia de observaciones.
, es decir, obtiene la secuencia óptima que mejor explica la secuencia de observaciones.
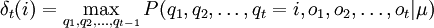
![\delta_{t+1}{(i)} = \biggl[\max_{1 \leq i \leq N}{\delta_{i}(a_{ij})}\biggr] b_{j}(o_{t+1})](images/math/a/7/d/a7d7611cdb00146284f53bc163ef4722.png)
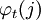 .
.
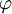 .
.
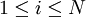
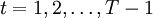 ,
, 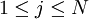
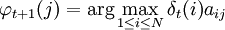 ,
,
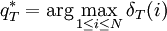
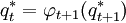 ,
,
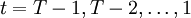
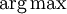 (en lugar de sumar las probabilidades) para calcular la secuencia de estados más probable.
(en lugar de sumar las probabilidades) para calcular la secuencia de estados más probable.

Acerca de quimica.es
Descubra toda la información interesante sobre nuestro portal especializado quimica.es.
Acerca de LUMITOS
Descubra más información sobre la empresa LUMITOS y nuestro equipo.
Anunciarse en LUMITOS
Descubra cómo puede ayudarle LUMITOS en su marketing online.
Los portales especializados de LUMITOS




© 1997-2026 LUMITOS AG, All rights reserved

