La inteligencia artificial potencia la microscopía de superresolución
Un nuevo modelo generativo calcula las imágenes con más eficacia que los enfoques establecidos
Anuncios



La inteligencia artificial generativa (IA) puede ser más conocida por aplicaciones de creación de textos o imágenes como ChatGPT o Stable Diffusion. Pero su utilidad va más allá y se está demostrando en campos científicos cada vez más diversos. En un trabajo reciente, que se presentará en la próxima Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR), investigadores del Centro para la Comprensión Avanzada de Sistemas (CASUS) del Helmholtz-Zentrum Dresden-Rossendorf (HZDR), en colaboración con colegas del Imperial College London y el University College London, han desarrollado un nuevo algoritmo de código abierto llamado Modelo de Difusión Variacional Condicional (CVDM). Basado en la IA generativa, este modelo mejora la calidad de las imágenes reconstruyéndolas a partir de la aleatoriedad. Además, el CVDM es computacionalmente menos costoso que los modelos de difusión establecidos, y puede adaptarse fácilmente a diversas aplicaciones.
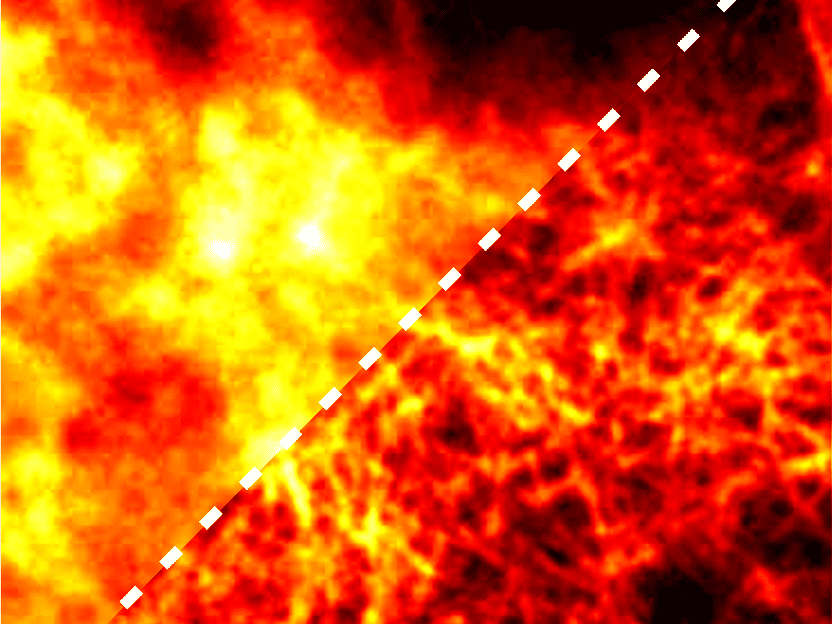
Una micrografía de fluorescencia tomada del conjunto de datos abierto de microscopía de superresolución BioSR.
Source: A. Yakimovich/CASUS, modified image from the BioSR dataset by Chang Qiao & Di Li (licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/)
Con la llegada de los macrodatos y los nuevos métodos matemáticos y de ciencia de datos, los investigadores tratan de descifrar fenómenos aún inexplicables en biología, medicina o ciencias medioambientales utilizando planteamientos de problemas inversos. Los problemas inversos tratan de recuperar los factores causales que conducen a determinadas observaciones. Tenemos una versión en escala de grises de una imagen y queremos recuperar los colores. En este caso suele haber varias soluciones válidas, ya que, por ejemplo, el azul claro y el rojo claro parecen idénticos en la imagen en escala de grises. Por lo tanto, la solución a este problema inverso puede ser la imagen con la camisa azul claro o la que tiene la camisa rojo claro.
El análisis de imágenes microscópicas también puede ser un problema inverso típico. "Tienes una observación: tu imagen microscópica. Aplicando algunos cálculos, puedes aprender más sobre tu muestra de lo que parece a primera vista", explica Gabriel della Maggiora, estudiante de doctorado en CASUS y autor principal del artículo del ICLR. Los resultados pueden ser imágenes de mayor resolución o mejor calidad. Sin embargo, el camino desde las observaciones, es decir, las imágenes microscópicas, hasta las "superimágenes" no suele ser obvio. Además, los datos de las observaciones suelen ser ruidosos, incompletos o inciertos. Todo ello aumenta la complejidad de la resolución de los problemas inversos, convirtiéndolos en apasionantes retos matemáticos.

El poder de los modelos generativos de IA como Sora
Una de las herramientas más potentes para abordar los problemas inversos es la IA generativa. En general, los modelos de IA generativa aprenden la distribución subyacente de los datos en un conjunto de datos de entrenamiento determinado. Un ejemplo típico es la generación de imágenes. Tras la fase de entrenamiento, los modelos de IA generativa generan imágenes completamente nuevas que, sin embargo, son coherentes con los datos de entrenamiento.
Entre las distintas variantes de IA generativa, una familia particular denominada modelos de difusión ha ganado popularidad recientemente entre los investigadores. Con los modelos de difusión, un proceso iterativo de generación de datos parte del ruido básico, un concepto utilizado en la teoría de la información para imitar el efecto de muchos procesos aleatorios que se dan en la naturaleza. En cuanto a la generación de imágenes, los modelos de difusión han aprendido qué disposiciones de píxeles son comunes y cuáles no en las imágenes del conjunto de datos de entrenamiento. Generan la nueva imagen deseada bit a bit hasta que una disposición de píxeles coincide mejor con la estructura subyacente de los datos de entrenamiento. Un buen ejemplo de la potencia de los modelos de difusión es Sora, el modelo de conversión de texto en vídeo de la empresa de software estadounidense OpenAI. Un componente de difusión implementado permite a Sora generar vídeos que parecen más realistas que cualquier otro modelo de IA creado hasta ahora.
Pero hay un inconveniente. "Los modelos de difusión son conocidos desde hace tiempo por su elevado coste computacional. Recientemente, algunos investigadores han renunciado a ellos precisamente por ese motivo", explica Artur Yakimovich, director de un grupo de jóvenes investigadores de CASUS y autor del artículo del ICLR. "Pero nuevos desarrollos como nuestro Modelo de Difusión Variacional Condicional permiten minimizar las 'ejecuciones improductivas', que no conducen al modelo final. Al reducir el esfuerzo computacional y, por tanto, el consumo de energía, este enfoque también puede hacer que el entrenamiento de los modelos de difusión sea más respetuoso con el medio ambiente."
El entrenamiento inteligente no sólo funciona en el deporte
Las "carreras improductivas" son un importante inconveniente de los modelos de difusión. Una de las razones es que el modelo es sensible a la elección del programa predefinido que controla la dinámica del proceso de difusión: Este programa rige cómo se añade el ruido: demasiado poco o demasiado, en el lugar equivocado o en el momento equivocado... hay muchos escenarios posibles que terminan con un entrenamiento fallido. Hasta ahora, este programa se ha establecido como un hiperparámetro que debe ajustarse para cada nueva aplicación. En otras palabras, al diseñar el modelo, los investigadores suelen estimar el horario elegido mediante el método de ensayo y error. En el nuevo trabajo presentado en el ICLR, los autores incorporan el horario ya en la fase de entrenamiento, de modo que su CVDM es capaz de encontrar el entrenamiento óptimo por sí solo. El modelo obtuvo mejores resultados que otros modelos basados en un programa predefinido.
Entre otras cosas, los autores demostraron la aplicabilidad del CVDM a un problema científico: la microscopía de superresolución, un típico problema inverso. La microscopía de superresolución pretende superar el límite de difracción, un límite que restringe la resolución debido a las características ópticas del sistema microscópico. Para superar este límite algorítmicamente, los científicos de datos reconstruyen imágenes de mayor resolución eliminando tanto el desenfoque como el ruido de las imágenes grabadas de resolución limitada. En este escenario, el CVDM arrojó resultados comparables o incluso superiores a los de los métodos utilizados habitualmente.
"Por supuesto, existen varios métodos para aumentar el significado de las imágenes microscópicas, algunos de ellos basados en modelos generativos de inteligencia artificial", afirma Yakimovich. "Pero creemos que nuestro enfoque tiene algunas propiedades nuevas y únicas que dejarán huella en la comunidad de la imagen, a saber, alta flexibilidad y velocidad con una calidad comparable o incluso mejor en comparación con otros enfoques de modelos de difusión. Además, nuestro CVDM proporciona pistas directas cuando no está muy seguro de la reconstrucción, una propiedad muy útil que marca el camino a seguir para abordar estas incertidumbres en nuevos experimentos y simulaciones."
Gabriel della Maggiora presentará este trabajo en forma de póster en la Conferencia Internacional sobre Aprendizaje de Representaciones (ICLR), que se celebrará anualmente el 8 de mayo en la sesión de pósters 3, a las 10:45 horas. Una breve charla pregrabada sobre el trabajo está disponible en el sitio web. La conferencia se organiza este año por primera vez desde 2017 de nuevo en Europa, concretamente en Viena (Austria). Tanto si se asiste in situ como por videoconferencia, es necesario un pase de pago para acceder al contenido. "El ICLR utiliza un proceso de revisión por pares doble ciego a través del portal OpenReview", explica Yakimovich. "Las revisiones van acompañadas de puntuaciones sugeridas por los pares; sólo se aceptan los trabajos con puntuaciones altas. La aceptación de nuestro artículo, por tanto, equivale a una alta consideración por parte de la comunidad".
Nota: Este artículo ha sido traducido utilizando un sistema informático sin intervención humana. LUMITOS ofrece estas traducciones automáticas para presentar una gama más amplia de noticias de actualidad. Como este artículo ha sido traducido con traducción automática, es posible que contenga errores de vocabulario, sintaxis o gramática. El artículo original en Inglés se puede encontrar aquí.
Publicación original


Más noticias del departamento ciencias





























