Poner orden y conocimiento en la avalancha de datos
Anuncios



En el marco de un proyecto financiado por el Fondo Austríaco para la Ciencia FWF, un grupo de investigación de la Universidad de Ciencias Aplicadas de St. Pölten ha desarrollado un entorno versátil para la visualización de datos en el que el conocimiento experto puede integrarse fácilmente.
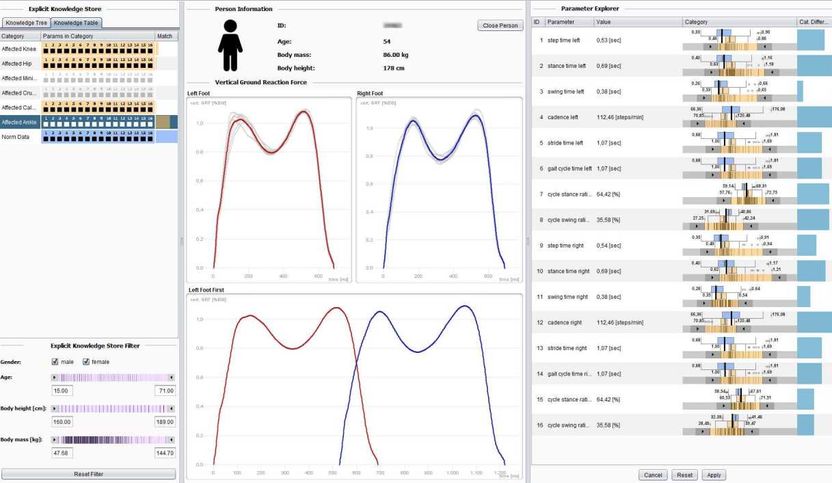
Una herramienta de software para el análisis de la marcha en fisioterapia que se desarrolló como parte del proyecto. Para generar conocimiento útil a partir de grandes cantidades de datos, la investigación está trabajando en métodos de visualización interactiva que combinan de manera óptima la inteligencia artificial y la experiencia humana.
KAVAGait/Screenshot
El procesamiento de grandes cantidades de datos es uno de los temas más importantes de nuestro tiempo, que actualmente es objeto de una intensa investigación. Mientras que algunos enfoques tratan de domar la avalancha de datos con métodos de inteligencia artificial, otros tratan de prepararlos mejor para los seres humanos. Un grupo de investigación dirigido por el informático Wolfgang Aigner está trabajando en la conexión de ambos enfoques y ha desarrollado nuevos métodos para presentar datos dependientes del tiempo de forma comprensible e integrar fácilmente conocimientos adicionales.
Combinando las fortalezas del hombre y la computadora
"Estamos aquí en el área de Visual Analytics, donde el objetivo es hacer que estos volúmenes de datos cada vez más grandes y complejos sean manejables", dice Wolfgang Aigner. Habla de una problemática "avalancha de información", a menudo contraproducente: "El objetivo no es tener más datos, sino descubrir algo". El procesamiento automatizado de la información es cada vez más importante, pero Aigner hace hincapié en la importancia que aún tienen las personas a la hora de interpretar los datos. "Los humanos somos extremadamente buenos para tratar con las sensaciones visuales, corregir errores o complementar datos incompletos", explica el investigador. "Los ordenadores, por otro lado, pueden procesar grandes cantidades de datos, siempre con la misma calidad. Los algoritmos informáticos y el procesamiento de la información humana son complementarios en muchas áreas". La idea de Visual Analytics es combinar ambas cosas: "Utilizamos lo que la gente sabe hacer y lo combinamos con lo que los ordenadores saben hacer".

Integrar el conocimiento experto
En un proyecto financiado por el Fondo Austríaco para la Ciencia (FWF), Aigner se ocupó específicamente del procesamiento de datos ordenados temporalmente, como los datos de mediciones médicas. "La hipótesis básica del proyecto era que debería ser posible integrar al menos una parte de estos conocimientos de fondo en el sistema informático y modelarlos allí para que puedan ser utilizados de nuevo por los seres humanos", dice el investigador. "Esta área ha recibido muy poca investigación previa." Así que Aigner y su equipo elaboraron una base teórica. "Nos concentramos en tres cosas", explica Aigner: "Poder descriptivo: ¿Puede el modelo describir tantos sistemas existentes como sea posible? ¿Puedo compararlas sistemáticamente? Luego está el Poder Evaluativo, el poder casi evaluador de un marco: ¿Puedo hacer una declaración sobre la calidad del resultado? Hay una descripción matemática del modelo donde se pueden comparar las cosas cuantitativamente. Finalmente, se consideró el Poder Generativo: ¿En qué medida el modelo me apoya en la construcción de nuevos sistemas? ¿Es un plano para otra cosa? Nuestro modelo se las arregla para cubrir estas tres áreas".
prototipos
Se realizaron dos estudios de caso como parte del proyecto. "Hemos aplicado los nuevos conceptos en dos situaciones de ejemplo, en primer lugar en la investigación de seguridad informática, concretamente en el análisis de malware, en lo que se refiere a la búsqueda de malware, y en segundo lugar en la fisioterapia, específicamente en el análisis de la marcha", explica Aigner. Para ello se desarrollaron prototipos de programas informáticos. Aigner explica el sistema utilizando como ejemplo el análisis de la marcha: "El paciente camina sobre una placa de medición de presión. Se miden los detalles del comportamiento de rodadura de los pies y se pueden extraer conclusiones a partir de los datos obtenidos, por ejemplo, sobre los problemas de rodilla o cadera". Después de registrar un ciclo completo de pasos, se derivan varios parámetros sobre la base del conocimiento experto utilizando métodos estadísticos. Este conocimiento experto debe ser fácilmente añadido en el curso de la aplicación.
"Como fisioterapeuta, por ejemplo, sé que una persona con una cierta combinación de valores de parámetros tiene un problema de menisco. En nuestro sistema, puedo marcar toda la serie de mediciones con el ratón y arrastrarla y soltarla en un área de la pantalla que he creado para los problemas de menisco. Contiene los datos de medición de las personas que tienen el problema, y así es como yo defino ese conocimiento". Cada nuevo conjunto de datos se compara automáticamente con los conjuntos de datos almacenados y si hay una característica similar, el programa lo indicará. Así que el ordenador analiza los datos, pero sólo hasta cierto punto, como explica Aigner: "Es importante que no busquemos automatizar completamente el diagnóstico, sino sólo dar soporte. El diagnóstico queda en manos de los expertos.
Fácil de usar y centralizado
El trabajo de Aigner se centra especialmente en el hecho de que las herramientas son fáciles de usar. "Cada barrera de acceso es un problema para los sistemas basados en el conocimiento en medicina, tecnología de la información y otras áreas", enfatiza el investigador. Allí, a menudo es necesario que alguien escriba código de programa o utilice métodos de modelado formal si se quiere integrar conocimientos adicionales. "El quid de la cuestión es que esto tiene que ocurrir fuera del trabajo con las herramientas." Por lo tanto, a menudo dura mucho tiempo o no ocurre en absoluto. "Nuestra idea en el proyecto era facilitar al usuario la integración de este conocimiento mientras trabaja, a través de la interfaz de usuario con el ratón, utilizando la función de arrastrar y soltar.
Uno de los dos prototipos todavía está en uso práctico. "En el área de análisis de malware, ya existía un proyecto de spin-off durante la vigencia del proyecto FWF, en el que se adaptó el prototipo junto con un socio de la empresa. El programa se utilizará allí internamente". En los proyectos de seguimiento, por un lado, los conceptos desarrollados se aplicarán aún más y, por otro, se añadirá una "sonificación" al procesamiento visual, es decir, al trabajo con sonidos.
Nota: Este artículo ha sido traducido utilizando un sistema informático sin intervención humana. LUMITOS ofrece estas traducciones automáticas para presentar una gama más amplia de noticias de actualidad. Como este artículo ha sido traducido con traducción automática, es posible que contenga errores de vocabulario, sintaxis o gramática. El artículo original en Alemán se puede encontrar aquí.
Publicación original
Wagner, M., Slijepcevic, D., Horsak, B., Rind, A., Zeppelzauer, M., & Aigner, W.; "KAVAGait: Knowledge-Assisted Visual Analytics for Clinical Gait Analysis"; IEEE Transactions on Visualization and Computer Graphics; 2018
Wagner, M., Rind, A., Thür, N., & Aigner, W.; "A knowledge-assisted visual malware analysis system: design, validation, and reflection of KAMAS"; Computers & Security; 2017


Más noticias del departamento ciencias




















Estos productos pueden interesarle